
动手实现第一个解释器
动手实现第一个解释器
第一个ANTLR文件
在项目src/main/下建立一个antlr文件夹,用于存储我们的ANTLR语法文件。
在src/main/antlr/文件夹内建立一个Expr.g4文件,将以下内容复制到文件中。
grammar Expr;
prog: (expr NEWLINE)* ;
expr: expr ('*'|'/') expr
| expr ('+'|'-') expr
| INT
| '(' expr ')'
;
NEWLINE : [\r\n]+ ;
INT : [0-9]+ ;
我们用ANTLR文件来定义我们想要处理的文本的文法规则。在这个文件里面,我们可以定义词法规则和语法规则;具体概念后续会解释。
在这个文件中,我们称从名称:到;为一个规则。一个规则下,可以有多个候选式,用|隔开候选式。候选式是从上到下匹配的,也就是说,优先级是从上往下的。
在这个文件中,我们可以看到,定义了一个四则运算,且乘除的优先级高于加减的优先级。值得一提的是,括号运算因为只有这个候选式,没有歧义(例如1+1*4是先计算1+1还是先计算1*4),因此不需要在最上头定义。

可视化测试我们的语法
在文件中,prog规则是我们的入口规则。可以看到,只有这个规则没有被其他规则引用,并提示"unused parser rule prog"。
右键prog规则,选择【Test Rule Prog】
这时候我们打开了一个窗口。
我们输入:(末尾有回车)
10+20*30
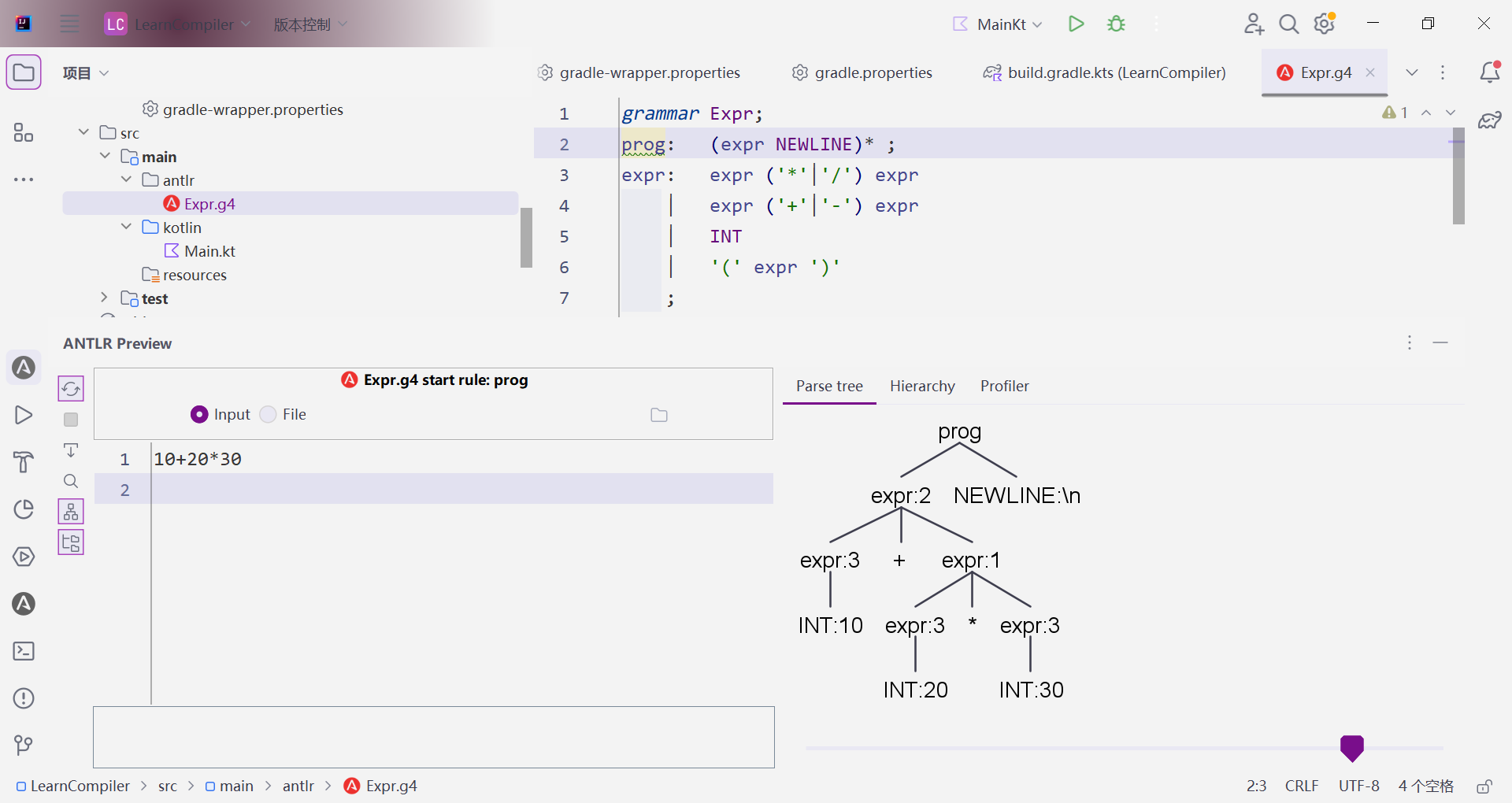
可以看到出现可视化的语法树。
我们分析这颗树:可以看到,语法解析是自上而下的,根据规则进行拆解的。
接下来我们输入:(末尾有回车)
10*20+30
对比两棵树,我们可以发现:在展开expr规则的时候,优先级最高的规则总是在树的下方。我们可以推测一下它到底是怎么匹配的——
10*20+30- 首先解析成INT(10) * INT(20) + INT(30)
- 根据候选式3(
expr: INT;), 解析成 expr * INT(20) + INT(30) - 根据候选式1(
expr: expr * expr;),解析成 expr + INT(30) - 根据候选式2(
expr: expr + expr;),解析成 expr
10+20*30- 首先解析成INT(10) + INT(20) * INT(30)
- 根据候选式3(
expr: INT;), 解析成 expr + INT(20) * INT(30) - 这时候解析成 expr + expr * INT(30),解析器为什么选择先处理后面的规则呢?
- 根据候选式1(
expr: expr * expr;),解析成 expr + expr - 根据候选式2(
expr: expr + expr;),解析成 expr
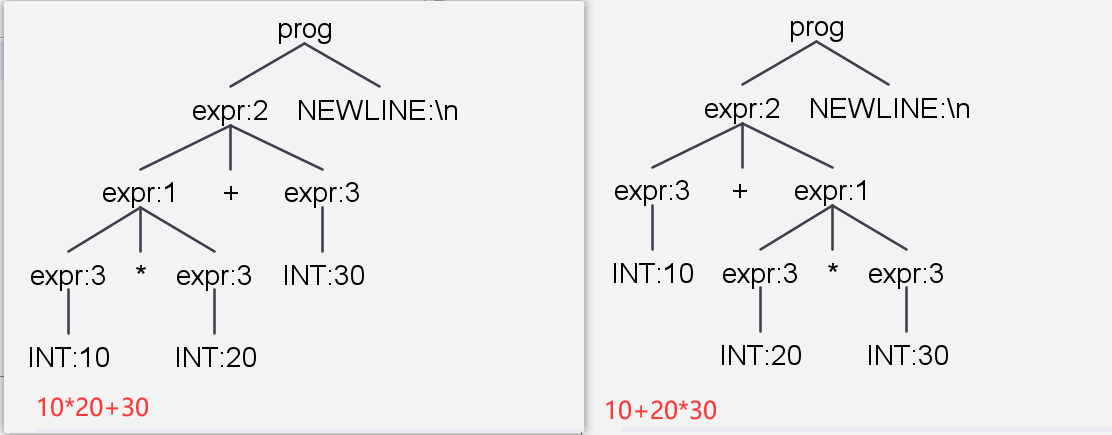
我们发现,很有可能的是,解析器往下读取了一个字符*,用于决策处理到底首先匹配哪个语法规则。
生成终结符表、语法分析器和词法分析器
点击右侧【大象图标】,在任务列表中找到【other/generateGrammarSource】,双击。
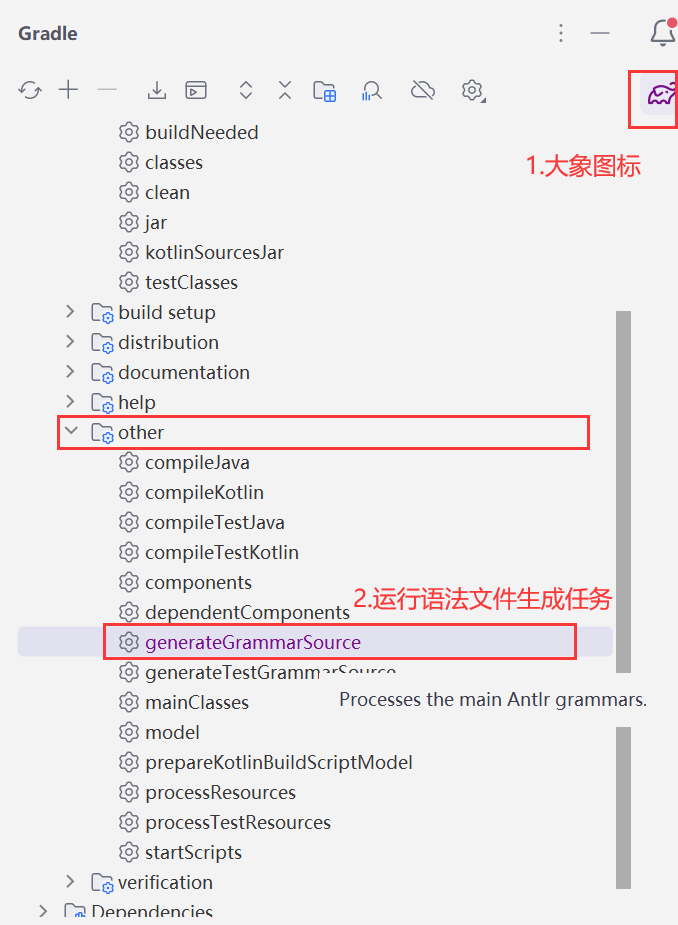
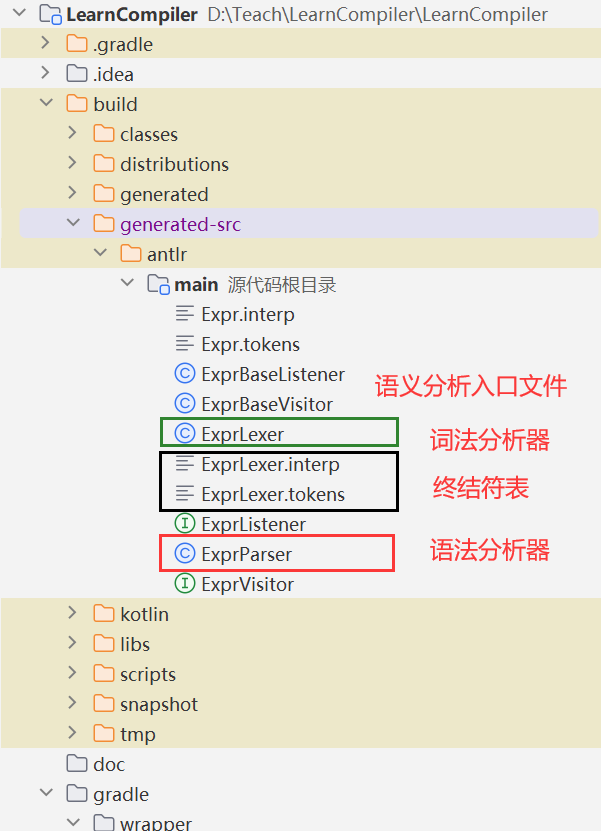
让我们看向项目文件夹下build/generated-src/antlr/main/,可以看到多了一些文件:
ExprLexer:词法分析器ExprParser:语法分析器ExprLexer.interp和ExprLexer.tokens:终结符文件ExprBaseVisitor和ExprBaseListener:语义分析的入口文件
这些文件到底代表着什么,这里先卖个关子,我们先关注实践。
初次运行我们的程序
更改Main.kt文件的代码
package org.example
import ExprLexer
import ExprParser
import org.antlr.v4.runtime.CharStreams
import org.antlr.v4.runtime.CommonTokenStream
fun main() {
val code = """
10+20*30
""".trimIndent()
//input:从输入中生成字符流
val input = CharStreams.fromString(code)
//lexer:将字符流导入词法分析器中
val lexer = ExprLexer(input)
//tokens:从词法分析器中获得属性字(单词)流
val tokens = CommonTokenStream(lexer)
//parser:将属性字流导入语法分析器中
val parser = ExprParser(tokens)
//tree:从语法分析器得到以语法规则`prog`为节点的语法树
val tree = parser.prog()
//打印语法树的结构
println(tree.toStringTree(parser))
}
可以看到我们的程序的运行流程,如下图所示:
根据这个流程,我们可以猜测编译器的工作原理。
我们运行程序。得到输出结果应该是:
(prog (expr (expr 10) + (expr (expr 20) * (expr 30))) \n)
这个结果和可视化的结果是一致的。
如果出现报错,请参照附录进行调整。
为我们的程序添加计算功能
为了更好地解析程序,稍微修改一下Expr.g4文件:用op标记一下运算符,以帮助我们判断。修改之后,执行【other/generateGrammarSource】任务。
grammar Expr;
prog: (expr NEWLINE)* ;
expr: expr op=('*'|'/') expr
| expr op=('+'|'-') expr
| INT
| '(' expr ')'
;
NEWLINE : [\r\n]+ ;
INT : [0-9]+ ;
在src/main/kotlin文件夹下新建Kotlin类文件ExprCalculateVisitor,使之继承ExprBaseVisitor。
ExprBaseVisitor是一个泛型类,我们要提供一个类型给它,这个类型是作为计算结果的类型,我们选择Int作为计算类型。
package org.example
import ExprBaseVisitor
class ExprCalculateVisitor: ExprBaseVisitor<Int>() {
}
现在,右键类体内空处,【生成】->【重写方法】
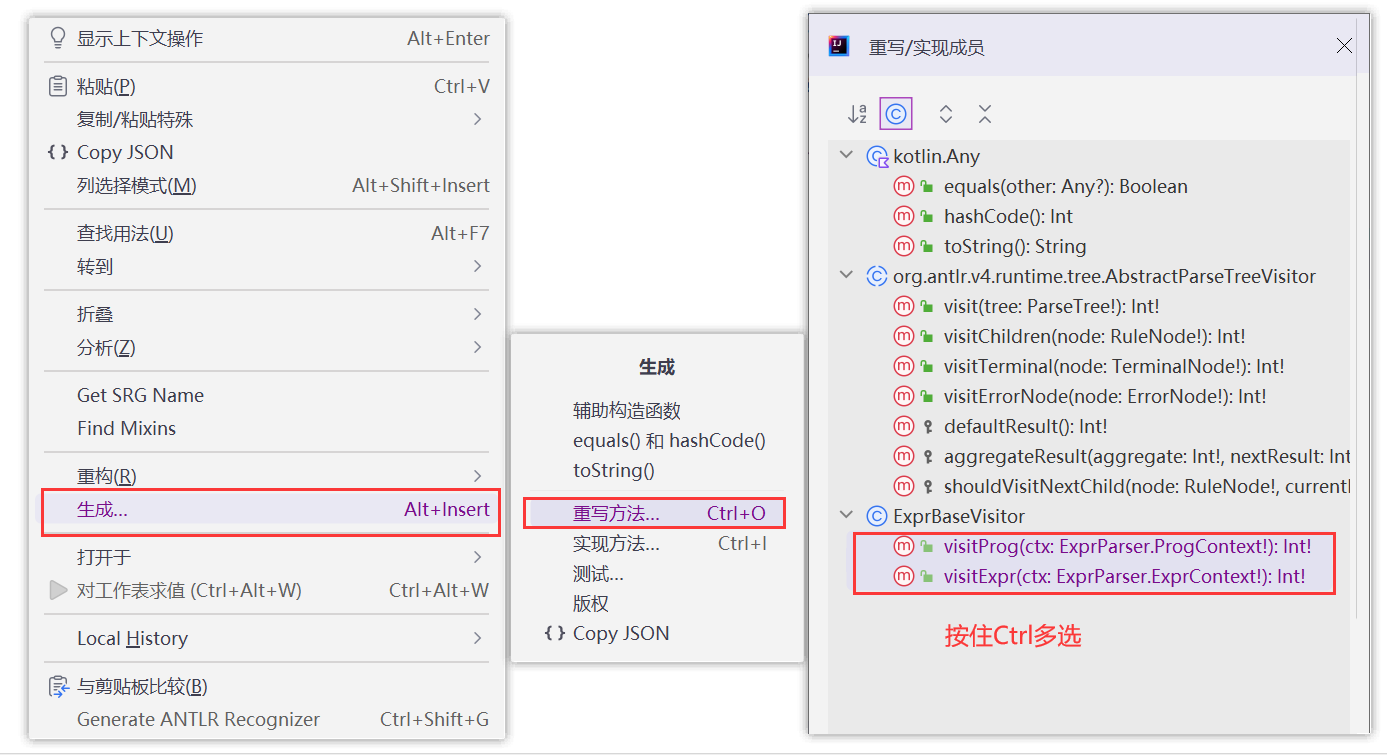
修改我们的代码。
ExprCalculateVisitor.kt
package org.example
import ExprBaseVisitor
class ExprCalculateVisitor: ExprBaseVisitor<Int>() {
//prog规则的入口函数 prog: (expr NEWLINE)* ;
override fun visitProg(ctx: ExprParser.ProgContext?): Int {
ctx?:throw Error()
for(exprContext in ctx.expr()){
//在这里遍历每一行的计算式
println(visit(exprContext))
}
return 0
}
//expr规则的入口函数
override fun visitExpr(ctx: ExprParser.ExprContext?): Int {
ctx?:throw Error()
if(ctx.expr().isEmpty()) return ctx.text.toInt() //expr: INT;
return when(ctx.op?.text){ //这里在括号规则时,没有op,因此用可选链
"+"-> visit(ctx.expr(0)) + visit(ctx.expr(1))
"-"-> visit(ctx.expr(0)) - visit(ctx.expr(1))
"*"-> visit(ctx.expr(0)) * visit(ctx.expr(1))
"/"-> visit(ctx.expr(0)) / visit(ctx.expr(1))
else-> visit(ctx.expr(0)) //expr: '(' expr ')';
}
}
}
同时更新我们的Main.kt,将Visitor加入进程序中。
package org.example
import ExprLexer
import ExprParser
import org.antlr.v4.runtime.CharStreams
import org.antlr.v4.runtime.CommonTokenStream
fun main() {
val code = """
10+20*30
""".trimIndent()
//input:从输入中生成字符流
val input = CharStreams.fromString(code)
//lexer:将字符流导入词法分析器中
val lexer = ExprLexer(input)
//tokens:从词法分析器中获得属性字(单词)流
val tokens = CommonTokenStream(lexer)
//parser:将属性字流导入语法分析器中
val parser = ExprParser(tokens)
//tree:从语法分析器得到以语法规则`prog`为节点的语法树
val tree = parser.prog()
//打印语法树的结构
println(tree.toStringTree(parser))
//visitor:调用语义分析器
val visitor = ExprCalculateVisitor()
//result:让语义分析器遍历语法树,得到结果
val result = visitor.visit(tree)
//打印结果
println(result)
}
运行程序,将会看到输出:
610
0
成功计算了结果!
现在更改val code定义的程序字符串,试试其他的式子是否支持吧!
遗留问题
- 终结符是什么?
- 词法分析是什么?
- 语法分析是什么?
- 编译器的运行流程是什么?
- Visitor是什么,Listener是什么?
- 语法树是什么?
- 语义分析是什么?
- ANTLR的工作原理是什么,为什么可以支持运算符的优先级?
- ANTLR g4文件的定义规则是怎么样的?
ANTLR是什么
ANTLR 是一个语法解析器生成工具。https://www.antlr.org/
ANTLR提供了两个方面的支持:
我们提供一个语言的语法词法定义文件(g4文件), 工具会将这个文件生成终结符表、词法分析器、语法分析器
它提供了一个语法解析的运行时(runtime), 它生成的语法分析器和词法分析器都是依赖这个运行时的。
附录:未调整编译任务流程报错
如果运行报错,请在build.gralde.kts文件内如下内容,调整Kotlin编译流程,在生成语法文件后再执行。
//添加在文件最上方
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
//添加在文件最下方
tasks.withType<KotlinCompile> {
dependsOn(tasks.generateGrammarSource)
}